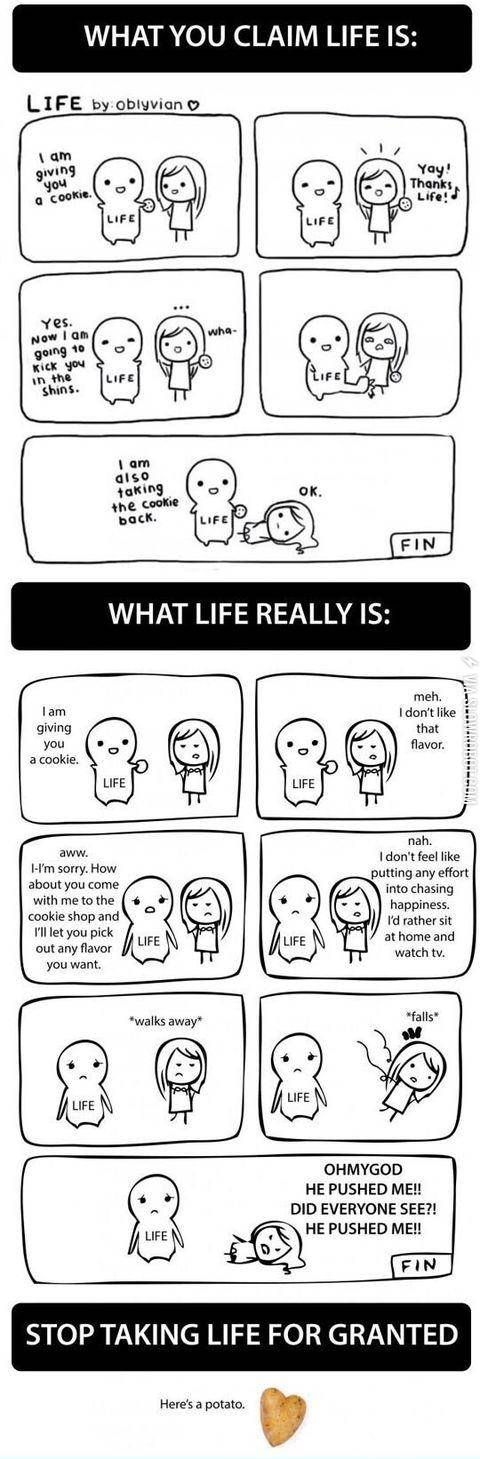
Finals Got Me Like SCORE 85

I Just Realized That I Grew Up. SCORE 69

My favorite gif of all time SCORE 97

Lonely AF Syndrome SCORE 47

I believe I can solve problems SCORE 51

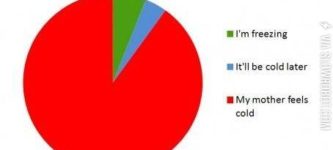
Partied hard last night SCORE 69

No regrets SCORE 86

Your societal judgements can go to hell SCORE 70

The struggles of being tall and thin SCORE 52

This sign in front of a church in my neighborhood. SCORE 76

I’m looking at you, Target SCORE 50

The Great Wall of USA SCORE 94

Orchid looks like a legendary pokemon SCORE 94

paper plane machine SCORE 87

What Is That You’re Holding? SCORE 42

Hsuehshan Tunnel SCORE 80

Gallon of paint before shaking SCORE 79

My wife bought the same book twice by mistake…How ironic… SCORE 78

Wave Photography SCORE 71
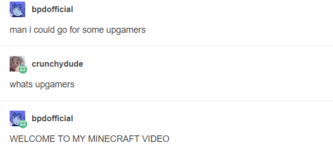
*obnoxious minute-long dubstep intro* SCORE 70

No Such Things As Too Many Naps SCORE 71

This hilarious "lost dog" poster I found a couple years ago. SCORE 66

The Best Things In Life Come In Cellophane SCORE 49

Let them eat diamonds SCORE 66

Hackerman SCORE 81

Every stereotype about Canada is true. SCORE 116

8 Earth years are roughly equal to 13 Venus years, meaning the two planets approximately trace out this pattern with amazing symmetry as they orbit the Sun. SCORE 102

never happens though SCORE 81

You’re Not From Here, Right? SCORE 111

Shocked prisoner witnesses fellow captive eaten by his captors SCORE 59

The one arcade game I could never beat SCORE 62

In light of Donald Trump’s latest executive orders SCORE 75